
쿼리 실행 구조
4장. 쿼리 실행 구조 요약
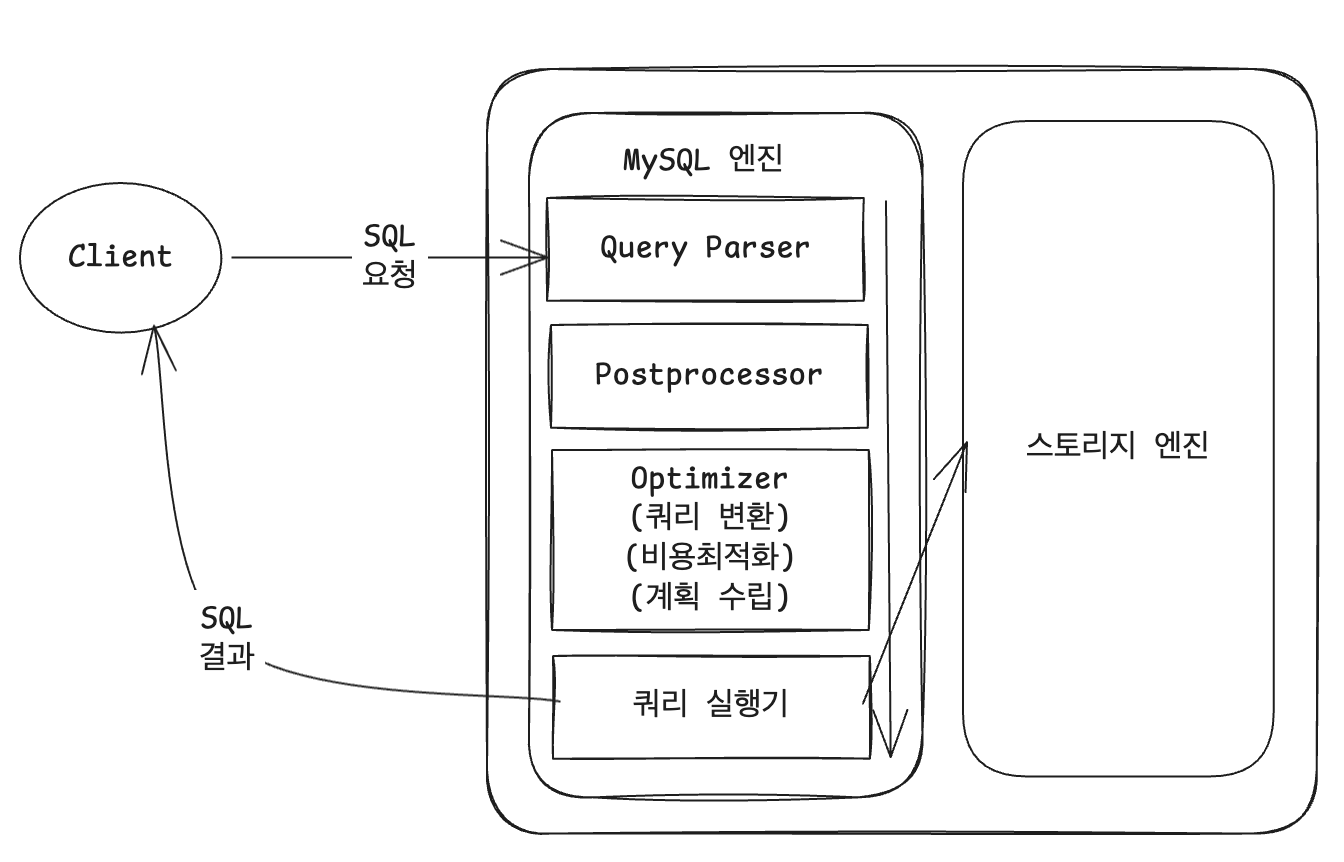
MySQL이 SQL 한 줄을 받아 결과를 돌려주기까지 거치는 단계는 명확하게 분리되어 있다. 이 구조를 이해하면 SQL 튜닝이나 실행 계획 분석이 왜 가능한지 그림이 그려진다.
전체 흐름
SQL → 쿼리 파서 → 전처리기 → 옵티마이저 → 실행 엔진 → 핸들러(스토리지 엔진) → 결과
파서부터 실행 엔진까지 MySQL 엔진에 속하고, 가장 아래의 핸들러가 스토리지 엔진에 속한다. 이 둘은 명확히 분리되어 있으며, 스토리지 엔진은 플러그인 형태로 교체 가능하다. InnoDB, MyISAM, MEMORY 등이 모두 같은 핸들러 인터페이스를 따른다.
쿼리 파서
사용자가 보낸 SQL 문장을 토큰(token) 단위로 잘라낸 뒤, 문법 규칙에 맞춰 파스 트리(Parse Tree)를 만든다. 여기서 언급하는 토큰은 광의에서 프로그래밍 언어론에서 학습하는 문장의 분해 단위를 의미하며, 여기에서는 DBMS가 인식할 수 있는 SQL 최소 단위의 어휘나 기호를 의미한다.
이 단계에서 SQL 문법 오류가 잡힌다. SELEC * FROM t 처럼 키워드가 틀리거나, 괄호가 짝이 안 맞는 경우 등이 여기서 걸러져 오류 메시지로 반환된다.
전처리기
파스 트리를 받아, 문법은 맞지만 의미적으로 잘못된 부분이 없는지 확인한다. 구체적으로 다음과 같은 일을 한다.
- 테이블, 컬럼, 함수 같은 객체가 실제로 존재하는지 검사
- 해당 객체에 접근할 권한이 있는지 검사
- 와일드카드(
*)를 실제 컬럼 목록으로 펼치는 작업
존재하지 않는 컬럼이나 권한 없는 테이블은 이 단계에서 걸러진다. 즉 파서를 통과해도 전처리기에서 떨어질 수 있다.
옵티마이저
DBMS의 두뇌라 불리는 부분이다. 전처리기를 통과한 쿼리를 가장 효율적으로 처리할 방법, 즉 실행 계획을 결정한다.
옵티마이저가 결정하는 것은 대략 이런 것들이다.
- 어떤 인덱스를 사용할지
- 조인 순서를 어떻게 잡을지
- 어떤 조인 알고리즘을 쓸지 (Nested Loop, Hash Join 등)
- 임시 테이블을 만들어야 하는지
같은 결과를 내는 쿼리라도 옵티마이저가 어떤 계획을 선택하느냐에 따라 실행 시간이 수십 배, 수백 배 차이가 날 수 있다. SQL 튜닝의 본질은 옵티마이저가 더 나은 계획을 고르도록 유도하는 작업이다.
실행 엔진
옵티마이저가 만든 실행 계획을 실제로 실행하는 단계다. 다만 실행 엔진이 직접 데이터를 디스크에서 읽거나 쓰는 것은 아니다. 실행 엔진은 계획에 따라 핸들러에게 요청을 던지고, 받은 결과를 다음 단계로 전달하는 조율자 역할을 한다.
핸들러 (스토리지 엔진)
가장 아래 단계로, 실제 디스크에 데이터를 쓰고 읽는 역할을 한다. 실행 엔진이 "이 인덱스에서 다음 레코드 하나 꺼내줘" 같은 요청을 보내면, 핸들러가 실제 데이터 파일에 접근해 결과를 돌려준다.
MySQL은 이 핸들러를 플러그인 구조로 설계해 두었기 때문에, 같은 SQL을 처리하더라도 테이블이 어떤 스토리지 엔진(InnoDB, MyISAM, MEMORY, Archive 등)을 사용하는지에 따라 실제 저장 방식이 완전히 달라진다.
한눈에 비교
| 단계 | 역할 | 잡아내는 오류 |
|---|---|---|
| 쿼리 파서 | SQL을 파스 트리로 변환 | 문법 오류 |
| 전처리기 | 객체 존재·권한 확인, * 펼치기 | 의미적 오류 |
| 옵티마이저 | 실행 계획 수립 | — |
| 실행 엔진 | 계획에 따라 핸들러 호출 | — |
| 핸들러 | 디스크 I/O 수행 | — |
댓글
아직 댓글이 없습니다.